.

📘 หลักสูตรอบรม
“พื้นฐาน Computer Vision และ Object Detection ด้วย AI”
1. หลักการของหลักสูตร
หลักสูตรนี้มุ่งเน้นให้ผู้เรียนเข้าใจการทำงานของ Computer Vision และ Object Detection ผ่านการลงมือปฏิบัติจริง โดยใช้ภาษา Python และเครื่องมือที่ใช้งานจริงในอุตสาหกรรม เช่น OpenCV และ YOLO World
ผู้เรียนจะได้เรียนรู้ตั้งแต่:
- การติดตั้งระบบ
- การเขียนโปรแกรมพื้นฐาน
- การประมวลผลภาพ
- การใช้ AI ตรวจจับวัตถุแบบ Real-time
โดยใช้โค้ดตัวอย่างจริงในการเรียนรู้ เพื่อให้สามารถนำไปต่อยอดได้ทันที
2. วัตถุประสงค์ของหลักสูตร
- เพื่อให้ผู้เรียนเข้าใจพื้นฐานของ Computer Vision
- เพื่อให้สามารถติดตั้งและใช้งาน Python สำหรับงาน AI ได้
- เพื่อให้เข้าใจหลักการของ Object Detection
- เพื่อให้สามารถใช้งาน YOLO World ตรวจจับวัตถุได้
- เพื่อให้สามารถพัฒนาโปรแกรมตรวจจับวัตถุแบบ Real-time
3. ความรู้พื้นฐาน AI และ Computer Vision
🔹 AI (Artificial Intelligence) คืออะไร

ปัญญาประดิษฐ์ หรือ Artificial Intelligence คือเทคโนโลยีที่ทำให้คอมพิวเตอร์สามารถ “คิด เรียนรู้ และตัดสินใจ” ได้คล้ายมนุษย์ โดยอาศัยการประมวลผลข้อมูลจำนวนมากและการสร้างแบบจำลองทางคณิตศาสตร์ หลักการสำคัญของ AI คือการให้เครื่องเรียนรู้จากข้อมูล แทนการเขียนคำสั่งแบบตายตัวเหมือนโปรแกรมทั่วไป หนึ่งในแนวทางหลักคือ Machine Learning ซึ่งเป็นการสอนให้คอมพิวเตอร์เรียนรู้รูปแบบจากข้อมูล เช่น การจำแนกภาพหรือการทำนายผลลัพธ์ อีกแนวทางที่สำคัญคือ Deep Learning ซึ่งใช้โครงข่ายประสาทเทียมหลายชั้นเพื่อเลียนแบบการทำงานของสมองมนุษย์ AI สามารถรับข้อมูลได้หลายรูปแบบ เช่น ข้อความ เสียง ภาพ และวิดีโอ แล้วนำมาวิเคราะห์เพื่อหาความสัมพันธ์หรือความหมาย ระบบ AI ทำงานโดยการฝึก (Training) จากข้อมูลจำนวนมาก แล้วนำความรู้ที่ได้ไปใช้กับข้อมูลใหม่ (Inference) ตัวอย่างการใช้งาน เช่น ผู้ช่วยอัจฉริยะ การแปลภาษา ระบบแนะนำสินค้า และรถยนต์ไร้คนขับ ในด้านภาพ AI ใช้ Computer Vision เพื่อให้เข้าใจสิ่งที่เห็น และในด้านภาษาใช้ Natural Language Processing เพื่อเข้าใจภาษามนุษย์ ข้อดีของ AI คือช่วยลดงานซ้ำ ๆ เพิ่มความแม่นยำ และทำงานได้รวดเร็ว อย่างไรก็ตาม AI ต้องใช้ข้อมูลที่มีคุณภาพ และอาจมีข้อผิดพลาดหากข้อมูลไม่เพียงพอ โดยสรุป AI คือเทคโนโลยีที่ทำให้เครื่องจักรสามารถเรียนรู้และพัฒนาได้เอง เพื่อช่วยมนุษย์แก้ปัญหาและตัดสินใจได้ดีขึ้นในโลกยุคดิจิทัล
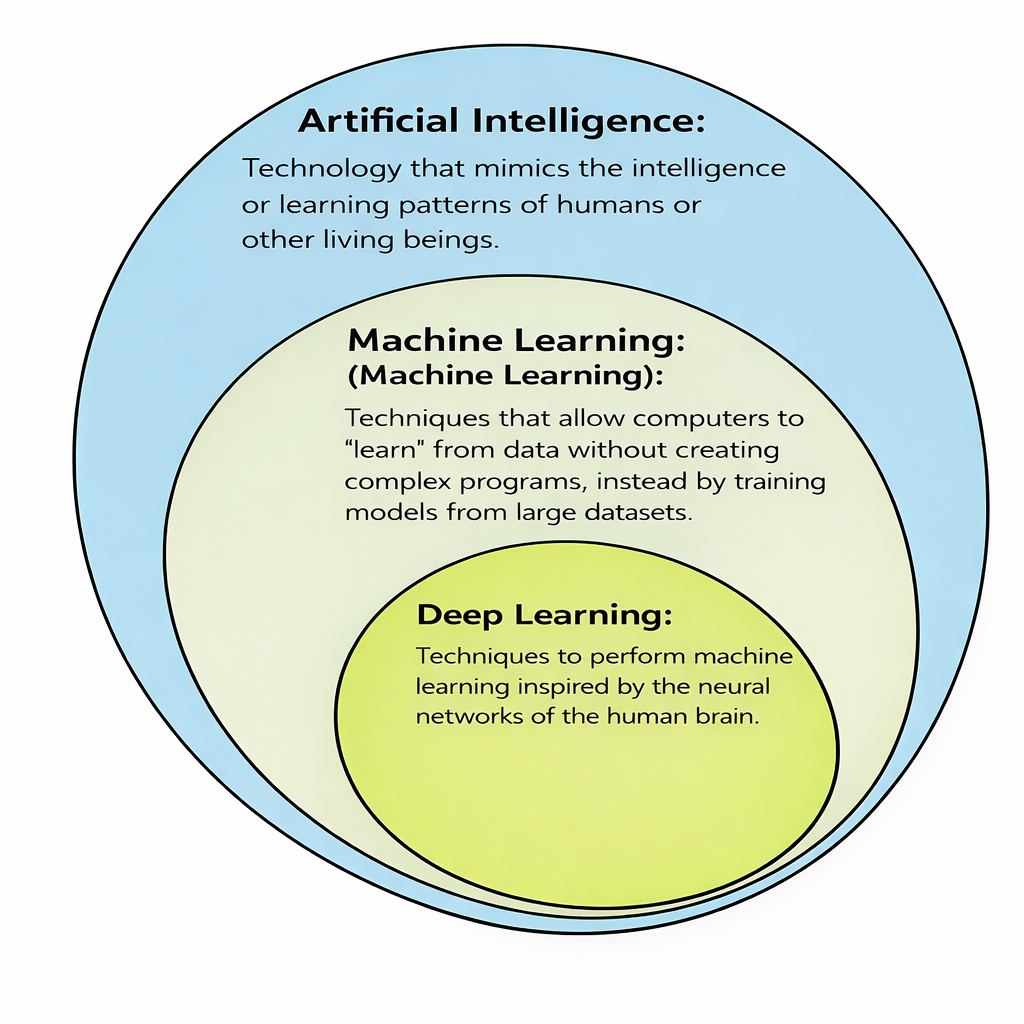
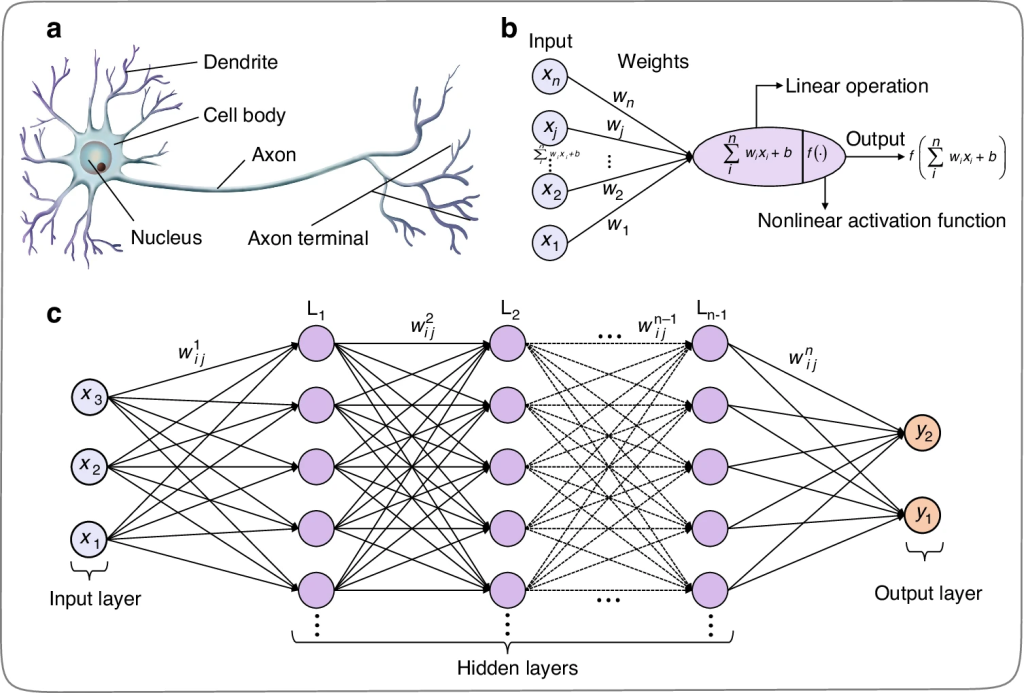
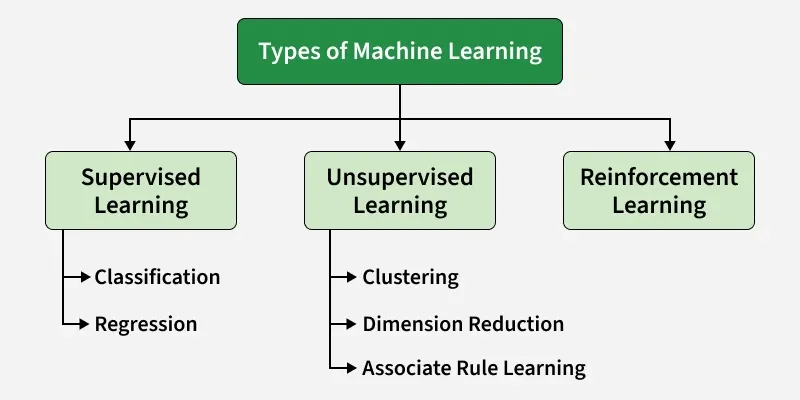
🔹 ชนิดของ Machine Learning
Machine Learning หรือ Machine Learning เป็นส่วนหนึ่งของ Artificial Intelligence ที่เน้นการทำให้คอมพิวเตอร์ “เรียนรู้จากข้อมูล” ได้เอง แทนที่จะต้องเขียนคำสั่งทุกขั้นตอนเหมือนโปรแกรมทั่วไป แนวคิดหลักคือให้ระบบดูข้อมูลจำนวนมาก แล้วค้นหารูปแบบ (pattern) ที่ซ่อนอยู่ จากนั้นนำรูปแบบนั้นไปใช้ตัดสินใจหรือคาดการณ์ในสถานการณ์ใหม่ ๆ เช่น การแยกภาพแมวกับสุนัข หรือการทำนายราคาสินค้า ระบบจะค่อย ๆ ฉลาดขึ้นเมื่อได้รับข้อมูลเพิ่มขึ้น เหมือนกับมนุษย์ที่เรียนรู้จากประสบการณ์
Machine Learning มีหลายประเภท โดยแต่ละแบบเหมาะกับงานต่างกัน เริ่มจาก Supervised Learning ซึ่งเป็นการเรียนรู้แบบมีคำตอบ ตัวอย่างเช่น มีรูปภาพพร้อมป้ายกำกับว่า “แมว” หรือ “สุนัข” ระบบจะเรียนรู้จากข้อมูลที่มีคำตอบนี้เพื่อนำไปใช้ทำนายข้อมูลใหม่ ต่อมาคือ Unsupervised Learning ซึ่งไม่มีคำตอบให้ ระบบต้องหาความสัมพันธ์หรือจัดกลุ่มข้อมูลเอง เช่น การแบ่งกลุ่มลูกค้าตามพฤติกรรม
อีกประเภทคือ Reinforcement Learning ซึ่งเป็นการเรียนรู้จาก “การลองผิดลองถูก” โดยมีรางวัล (reward) หรือบทลงโทษ (penalty) เช่น การสอนหุ่นยนต์ให้เดิน หรือ AI เล่นเกมให้เก่งขึ้น นอกจากนี้ยังมี Semi-Supervised Learning ที่ใช้ทั้งข้อมูลที่มีคำตอบและไม่มีคำตอบร่วมกัน ช่วยลดภาระในการเตรียมข้อมูล และ Self-Supervised Learning ที่ให้ระบบสร้างคำตอบขึ้นมาเองจากข้อมูล เช่น การทำนายส่วนที่หายไปของข้อมูล
โดยรวมแล้ว Machine Learning คือหัวใจสำคัญของ AI ในปัจจุบัน เพราะช่วยให้ระบบสามารถเรียนรู้ ปรับตัว และพัฒนาได้เอง ทำให้ถูกนำไปใช้ในหลายด้าน เช่น การแพทย์ ธุรกิจ การเงิน และเทคโนโลยีอัจฉริยะต่าง ๆ
AI ในมุมมองของการวิเคราะห์ภาพและวิดีโออัจฉริยะ คือเทคโนโลยีที่ทำให้คอมพิวเตอร์สามารถ “มองเห็นและเข้าใจ” สิ่งที่อยู่ในภาพหรือวิดีโอได้เหมือนมนุษย์ โดยอาศัยองค์ความรู้จากสาขา Computer Vision ซึ่งเป็นส่วนหนึ่งของ Artificial Intelligence ที่เน้นการประมวลผลข้อมูลภาพ ระบบ AI จะรับข้อมูลจากกล้องหรือไฟล์วิดีโอ แล้วนำมาวิเคราะห์เพื่อค้นหารูปแบบหรือวัตถุที่สำคัญ จากนั้นจะใช้โมเดลที่เรียนรู้จากข้อมูลจำนวนมาก เช่น การตรวจจับวัตถุ (Object Detection) การจำแนกภาพ (Image Classification) และการติดตามวัตถุ (Object Tracking) เพื่อให้เข้าใจว่าในภาพมีอะไรเกิดขึ้น นอกจากนี้ AI ยังสามารถวิเคราะห์พฤติกรรม เช่น การเดิน การวิ่ง หรือเหตุการณ์ผิดปกติในวิดีโอได้ เทคโนโลยีนี้ใช้หลักการของ Deep Learning และ Neural Network เพื่อเลียนแบบการทำงานของสมองมนุษย์ ทำให้ระบบสามารถเรียนรู้และปรับปรุงความแม่นยำได้เองเมื่อมีข้อมูลเพิ่มขึ้น ในงานจริง AI ถูกนำไปใช้ในหลายด้าน เช่น ระบบกล้องวงจรปิดอัจฉริยะ รถยนต์ไร้คนขับ การแพทย์ และโรงงานอุตสาหกรรม จุดเด่นสำคัญคือสามารถประมวลผลได้รวดเร็วและทำงานแบบอัตโนมัติแบบเรียลไทม์ อย่างไรก็ตาม AI ยังมีข้อจำกัด เช่น ต้องใช้ข้อมูลจำนวนมากในการฝึก และอาจเกิดความผิดพลาดได้หากข้อมูลไม่ครบถ้วน โดยรวมแล้ว AI ด้านการวิเคราะห์ภาพและวิดีโอคือเครื่องมือสำคัญที่ช่วยให้เครื่องจักร “เข้าใจโลกผ่านภาพ” และนำไปสู่การตัดสินใจที่ชาญฉลาดมากขึ้นในอนาคต
1. Supervised Machine Learning
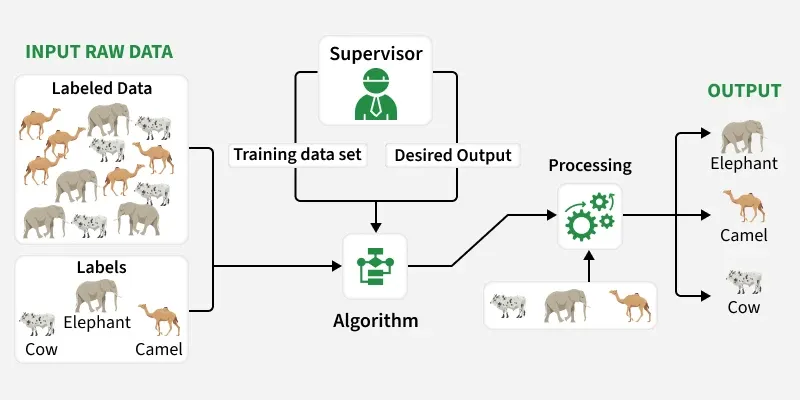
Supervised Machine Learning คือรูปแบบหนึ่งของ Machine Learning ที่สอนให้คอมพิวเตอร์เรียนรู้จาก “ข้อมูลที่มีคำตอบอยู่แล้ว”
ข้อมูลที่ใช้จะประกอบด้วย Input (ข้อมูลเข้า) และ Output (คำตอบ) เช่น รูปภาพ + ป้ายกำกับว่าเป็น “แมว” หรือ “สุนัข”
ระบบจะเรียนรู้ความสัมพันธ์ระหว่างข้อมูลและคำตอบ เพื่อใช้ทำนายข้อมูลใหม่ในอนาคต
ตัวอย่างการใช้งาน เช่น การจำแนกอีเมลสแปม การทำนายราคาบ้าน และการรู้จำภาพ
กระบวนการทำงานคือ ป้อนข้อมูล → ฝึกโมเดล → ทดสอบ → ปรับปรุงให้แม่นยำขึ้น
โมเดลจะพยายามลดความผิดพลาดระหว่างค่าที่ทำนายกับค่าจริงให้เหลือน้อยที่สุด
ข้อดีคือมีความแม่นยำสูง เพราะมีคำตอบช่วยสอน
ข้อจำกัดคือ ต้องใช้ข้อมูลที่มีการติดป้ายกำกับจำนวนมาก ซึ่งอาจใช้เวลาและค่าใช้จ่ายสูง
2. Unsupervised Machine Learning
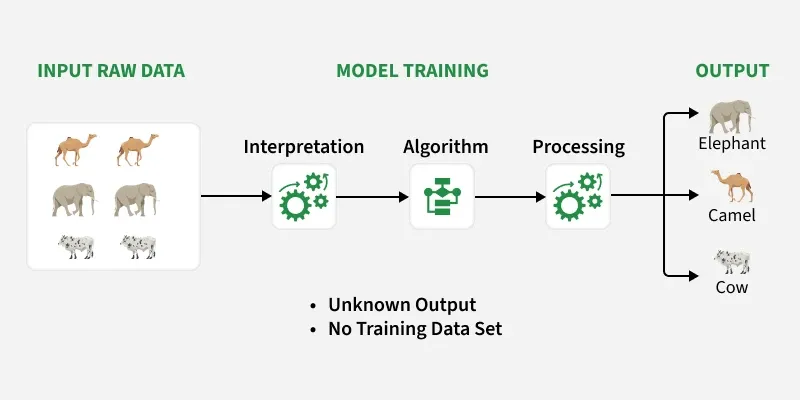
Unsupervised Machine Learning คือรูปแบบหนึ่งของ Machine Learning ที่ให้คอมพิวเตอร์เรียนรู้จาก “ข้อมูลที่ไม่มีคำตอบกำกับ”ระบบจะต้องค้นหารูปแบบหรือความสัมพันธ์ในข้อมูลด้วยตัวเอง โดยไม่รู้ล่วงหน้าว่าคำตอบคืออะไร
เปรียบเหมือนการให้เด็กดูของหลาย ๆ อย่างแล้วให้จัดกลุ่มเองตามความคล้ายกันงานที่พบบ่อยคือ “การจัดกลุ่มข้อมูล” (Clustering) เช่น แบ่งกลุ่มลูกค้าตามพฤติกรรมการซื้อ อีกตัวอย่างคือ “การลดมิติข้อมูล” เพื่อให้ข้อมูลซับซ้อนดูเข้าใจง่ายขึ้นระบบจะพยายามหาความเหมือนหรือความแตกต่างของข้อมูลแต่ละรายการ
ข้อดีคือไม่ต้องเสียเวลาเตรียมคำตอบ (label) เหมือนแบบ Supervised เหมาะกับข้อมูลขนาดใหญ่ที่ยังไม่รู้โครงสร้างหรือรูปแบบ
ข้อเสียคือผลลัพธ์อาจตีความยาก และบางครั้งไม่ตรงกับที่มนุษย์คาดหวัง โดยรวมคือการให้ AI “ค้นพบความรู้ใหม่” จากข้อมูลด้วยตัวเอง
3. Reinforcement Learning
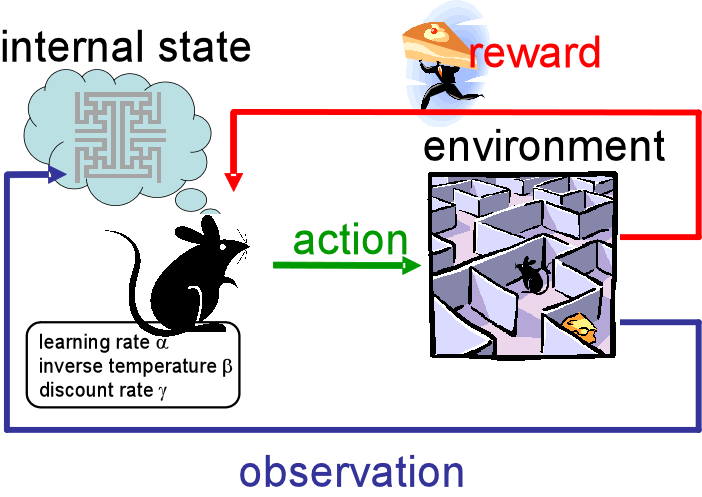
Reinforcement Learning เป็นรูปแบบหนึ่งของ Machine Learning ที่สอนให้คอมพิวเตอร์เรียนรู้ผ่าน “การลองผิดลองถูก” คล้ายกับการฝึกสัตว์หรือการเรียนรู้ของมนุษย์ในชีวิตจริง โดยระบบจะมีตัวแทน (Agent) ที่ทำหน้าที่ตัดสินใจเลือกการกระทำในสภาพแวดล้อม (Environment) ทุกครั้งที่ Agent ทำบางอย่าง ระบบจะได้รับ “รางวัล” (Reward) หากทำถูก หรือ “บทลงโทษ” (Penalty) หากทำผิด จากนั้น Agent จะนำผลลัพธ์เหล่านี้ไปปรับปรุงการตัดสินใจในครั้งต่อไป เป้าหมายหลักคือการเรียนรู้ให้ได้ผลลัพธ์ที่ดีที่สุดในระยะยาว ไม่ใช่แค่ครั้งเดียว เช่น การสอนหุ่นยนต์ให้เดิน การให้ AI เล่นเกม หรือการควบคุมรถยนต์ไร้คนขับ ในช่วงแรกระบบอาจทำผิดบ่อย แต่เมื่อเรียนรู้มากขึ้นจะค่อย ๆ เก่งขึ้นและเลือกวิธีที่ดีที่สุดได้ แนวคิดสำคัญคือการหาสมดุลระหว่าง “การลองสิ่งใหม่” (Exploration) และ “การใช้สิ่งที่รู้แล้ว” (Exploitation) ข้อดีของ Reinforcement Learning คือสามารถแก้ปัญหาที่ซับซ้อนและไม่มีคำตอบตายตัวได้ดี แต่ข้อเสียคือใช้เวลาฝึกนานและต้องออกแบบระบบรางวัลให้เหมาะสม หากออกแบบไม่ดีอาจทำให้ระบบเรียนรู้ผิดทางได้ โดยสรุป Reinforcement Learning คือการทำให้ AI เรียนรู้จากประสบการณ์ของตัวเอง จนสามารถตัดสินใจได้อย่างชาญฉลาดในสถานการณ์ต่าง ๆ
🔹 Object Detection คืออะไร
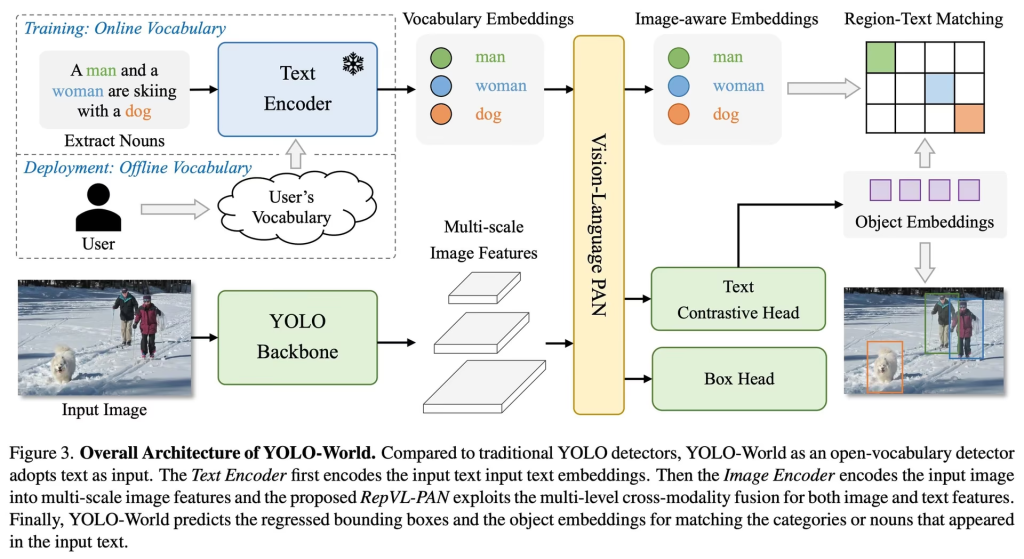
ภาพนี้อธิบายการทำงานของ YOLO-World ซึ่งเป็น AI ที่สามารถ “มองภาพและเข้าใจคำพูด” ไปพร้อมกันได้ โดยเริ่มจากด้านซ้ายบน ในช่วง Training จะมีประโยค เช่น “ผู้ชายและผู้หญิงกำลังเล่นสกีกับสุนัข” แล้วระบบจะดึงคำสำคัญอย่าง man, woman, dog ออกมา จากนั้นส่งเข้า Text Encoder เพื่อแปลงคำเป็นตัวเลขที่คอมพิวเตอร์เข้าใจได้ ต่อมาจะเกิดเป็น Vocabulary Embeddings ซึ่งเหมือนรหัสแทนคำแต่ละคำ เช่น สีเขียวแทน man สีฟ้าแทน woman และสีส้มแทน dog แล้วข้อมูลภาพจริงจากกล้องจะถูกส่งเข้า YOLO Backbone เพื่อวิเคราะห์หาวัตถุในภาพ ระบบจะสร้างคุณลักษณะของภาพหลายระดับ (multi-scale) เพื่อมองทั้งวัตถุเล็กและใหญ่ จากนั้นข้อมูลภาพจะถูกส่งไปยังส่วนที่เรียกว่า Vision-Language PAN ซึ่งทำหน้าที่รวมข้อมูล “ภาพ” กับ “คำ” เข้าด้วยกัน ทำให้ AI รู้ว่าวัตถุไหนตรงกับคำไหน ต่อมาในส่วน Image-aware Embeddings จะเป็นการปรับข้อมูลคำให้เข้ากับภาพจริงมากขึ้น จากนั้นระบบจะทำการจับคู่ระหว่างตำแหน่งวัตถุในภาพกับคำ (Region-Text Matching) เหมือนการเล่นเกมจับคู่ภาพกับคำตอบ สุดท้าย Box Head จะวาดกรอบสี่เหลี่ยมล้อมรอบวัตถุ เช่น คนหรือสุนัข และ Text Contrastive Head จะช่วยตัดสินว่าวัตถุนั้นคืออะไรตามคำที่กำหนด ด้านล่างซ้ายยังแสดงภาพจริงที่มีคนและสุนัข ซึ่งถูกตรวจจับและใส่กรอบสีต่าง ๆ อย่างถูกต้อง ส่วน Deployment ด้านซ้ายล่างหมายถึงตอนใช้งานจริง ผู้ใช้สามารถพิมพ์คำอะไรก็ได้ เช่น “dog” แล้วระบบจะค้นหาวัตถุนั้นในภาพได้ทันที ทำให้ YOLO-World ฉลาดและยืดหยุ่นมากกว่า AI แบบเดิมที่ต้องฝึกสอนล่วงหน้า
4. เครื่องมือที่ใช้ในหลักสูตร
- Python
- OpenCV → จัดการภาพ / กล้อง
- Ultralytics YOLO World → AI ตรวจจับวัตถุ
5. ขั้นตอนการเรียน (Step-by-Step)
🔹 ขั้นที่ 1: ติดตั้งโปรแกรมพื้นฐาน
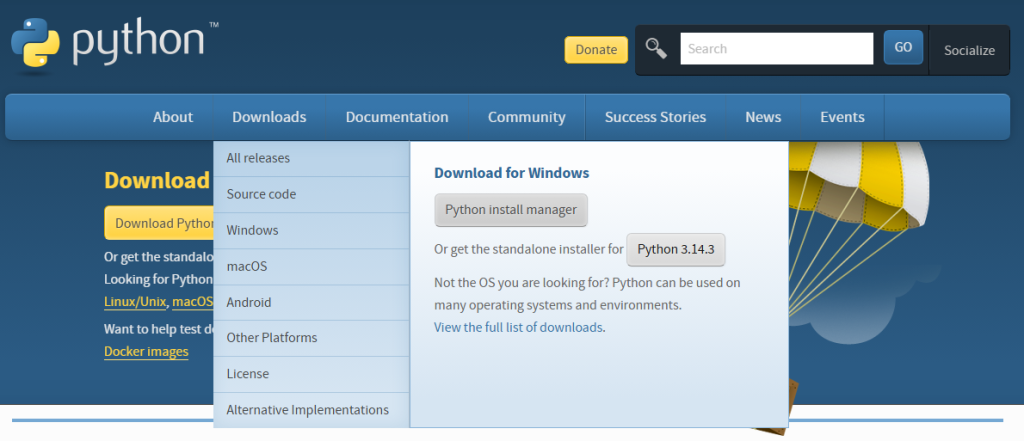
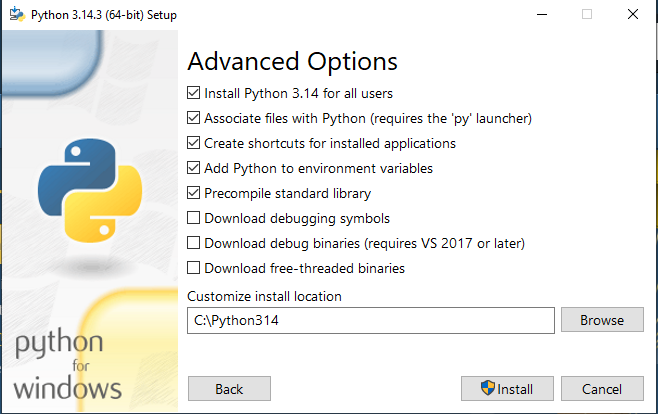
✅ 1. ติดตั้ง Python
- ดาวน์โหลดจาก: https://www.python.org/downloads/
- แนะนำเวอร์ชัน: 3.10 – 3.11
- ⚠️ ต้องติ๊ก “Add Python to PATH”
✅ 2. ติดตั้ง VS Code
- ดาวน์โหลด: https://code.visualstudio.com/download
- ติดตั้ง Extension:
- Python
- Pylance
✅ 3. ตรวจสอบการติดตั้ง
เปิด Terminal แล้วพิมพ์:
python --version
pip --version
🔹 ขั้นที่ 2: สร้างโปรเจกต์
mkdir ai-object-detection
cd ai-object-detection
🔹 ขั้นที่ 3: สร้าง Virtual Environment (แนะนำ)
python -m venv venv
เปิดใช้งาน:
- Windows:
venv\Scripts\activate
🔹 ขั้นที่ 4: ติดตั้ง Library
pip install opencv-python
pip install ultralytics
หรือ
pip install ultralytics opencv-pythonC:/Python314/python.exe -m pip install --upgrade pip
C:/Python314/python.exe -m pip install opencv-python
C:/Python314/python.exe -m pip install matplotlib
C:/Python314/python.exe -m pip install numpy
C:/Python314/python.exe -m pip install ultralytics
หรือ
C:/Python311/python.exe -m pip install ultralytics opencv-python matplotlib numpy🔹 ขั้นที่ 5: หลักการทำงานของโค้ด (อธิบายทีละส่วน)
🧠 1. โหลด Library
import cv2
from ultralytics import YOLOWorld
cv2→ ใช้จัดการภาพและกล้องYOLOWorld→ โมเดล AI
⚙️ 2. ตั้งค่า
MODEL_SIZE = "yolov8s-worldv2.pt" # เปลี่ยนเป็น "yolov8n-worldv2.pt" ถ้าต้องการเร็วสุด
CONF_THRESHOLD = 0.30 # ความมั่นใจขั้นต่ำ (0.25 - 0.45)
CLASSES = ["person"]
- MODEL → ขนาดโมเดล
- CONF → ความมั่นใจ
- CLASSES → กำหนดสิ่งที่อยากตรวจจับ
🤖 3. โหลดโมเดล AI
model = YOLOWorld(MODEL_SIZE)
model.set_classes(CLASSES)👉 ครั้งแรกจะโหลดไฟล์จากอินเทอร์เน็ต
🎯 4. เปิดกล้อง
cap = cv2.VideoCapture(0)
- 0 = กล้องหลัก
🔁 5. อ่านภาพแบบ Real-time
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
🔍 6. ตรวจจับวัตถุ
while True:
ret, frame = cap.read()
if not ret:
print(" ไม่สามารถอ่านภาพจากเว็บแคม")
break
results = model.predict(
source=frame,
conf=CONF_THRESHOLD,
iou=0.45,
verbose=False # ปิดข้อความ log
)
🖼️ 7. วาดกรอบ
annotated_frame = results[0].plot(
line_width=3, # ความหนาของกรอบ
font_size=18, # ขนาดตัวอักษร
conf=True, # แสดง confidence
labels=True
)
📺 8. แสดงผล
cv2.imshow("i-TDI Object Detection", annotated_frame)
⛔ 9. กด q เพื่อออก
if cv2.waitKey(1) & 0xFF == ord('q'):
break
🔹 ขั้นที่ 6: Workshop (Hands-on)
🎯 กิจกรรมที่ 1
- ตรวจจับ “คน” และ “โทรศัพท์”
🎯 กิจกรรมที่ 2
- เปลี่ยน CLASSES เช่น:
["man","woman","child"]
| Index | Class Name | Index | Class Name | Index | Class Name |
|---|---|---|---|---|---|
| 0 | person | 27 | tie | 54 | donut |
| 1 | bicycle | 28 | suitcase | 55 | cake |
| 2 | car | 29 | frisbee | 56 | chair |
| 3 | motorcycle | 30 | skis | 57 | couch |
| 4 | airplane | 31 | snowboard | 58 | potted plant |
| 5 | bus | 32 | sports ball | 59 | bed |
| 6 | train | 33 | kite | 60 | dining table |
| 7 | truck | 34 | baseball bat | 61 | toilet |
| 8 | boat | 35 | baseball glove | 62 | tv |
| 9 | traffic light | 36 | skateboard | 63 | laptop |
| 10 | fire hydrant | 37 | surfboard | 64 | mouse |
| 11 | stop sign | 38 | tennis racket | 65 | remote |
| 12 | parking meter | 39 | bottle | 66 | keyboard |
| 13 | bench | 40 | wine glass | 67 | cell phone |
| 14 | bird | 41 | cup | 68 | microwave |
| 15 | cat | 42 | fork | 69 | oven |
| 16 | dog | 43 | knife | 70 | toaster |
| 17 | horse | 44 | spoon | 71 | sink |
| 18 | sheep | 45 | bowl | 72 | refrigerator |
| 19 | cow | 46 | banana | 73 | book |
| 20 | elephant | 47 | apple | 74 | clock |
| 21 | bear | 48 | sandwich | 75 | vase |
| 22 | zebra | 49 | orange | 76 | scissors |
| 23 | giraffe | 50 | broccoli | 77 | teddy bear |
| 24 | backpack | 51 | carrot | 78 | hair drier |
| 25 | umbrella | 52 | hot dog | 79 | toothbrush |
| 26 | handbag | 53 | pizza | – | – |
🎯 กิจกรรมที่ 3
- ปรับค่า CONF_THRESHOLD
- ดูผลลัพธ์ที่เปลี่ยน
🎯 กิจกรรมที่ 4 (Advanced)
- ปิดการกำหนด class → ใช้ Open Vocabulary
model.set_classes(CLASSES)6. ปัญหาที่พบบ่อย (Troubleshooting)
❌ เปิดกล้องไม่ได้
- เช็ค device index:
cv2.VideoCapture(1)
เพิ่มเติมสำหรับการติดตั้ง git และ เรียกใช้ function การแปลง label เป็น class
เข้าไปที่
https://git-scm.com/install/windows
ติดตั้ง
https://github.com/git-for-windows/git/releases/download/v2.53.0.windows.2/Git-2.53.0.2-64-bit.exe
รันคำสั่งเพื่อติดตั้ง git
winget install --id Git.Git -e --source winget
เพิ่ม path ใน windows
กด Windows + S
พิมพ์:Environment Variables
เพิ่ม path
C:\Program Files\Git\bin
C:\Program Files\Git\cmd
ทดสอบเวอร์ชั่น git
git --version
ติดตั้ง clip
pip install git+https://github.com/ultralytics/CLIP.git
หรือ
C:\Python314\python.exe -m pip install git+https://github.com/ultralytics/CLIP.git
LInk:https://docs.ultralytics.com/models/yolo-world/
https://www.nature.com/articles/s41377-024-01590-3
https://www.geeksforgeeks.org/machine-learning/types-of-machine-learning
https://glasswing.vc/blog/ai-atlas-19-reinforcement-learning-rl/
https://unsplash.com/s/photos/portrait
https://cloudconvert.com/avif-to-jpg
https://theailearner.com/2019/01/01/image-negatives/
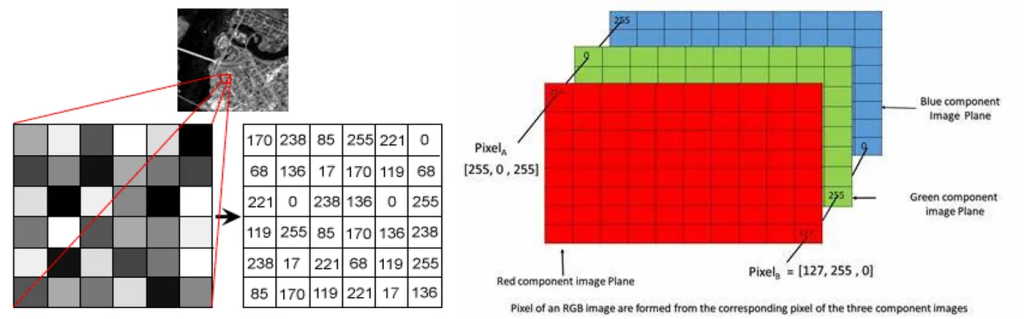
https://medium.com/@abhapratiti27/image-processing-basics-understanding-pixels-image-sizes-formats-transformations-and-a62d5868ce25
# Real-time Object Detection (เวอร์ชัน เฉลย)
# อัปเดตล่าสุด: 2024-06-01
# โดย: i-TDI Team (https://www.i-tdi.com)
# Powered by Chaloecmhai lowongtrakool
import cv2
from ultralytics import YOLOWorld
MODEL_SIZE = "yolov8s-worldv2.pt"
CONF_THRESHOLD = 0.30 # ความมั่นใจขั้นต่ำ (0.25 - 0.45)
CLASSES = ["man", "person", "woman", "child", "glasses", "phone", "laptop",
"car", "chair", "bottle", "book", "tv", "dog", "cat"]
model = YOLOWorld(MODEL_SIZE)
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 640)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 480)
if not cap.isOpened():
print("ไม่สามารถเปิดเว็บแคมได้")
exit()
while True:
ret, frame = cap.read()
if not ret:
print(" ไม่สามารถอ่านภาพจากเว็บแคม")
break
results = model.predict(
source=frame,
conf=CONF_THRESHOLD,
iou=0.45,
verbose=False
)
annotated_frame = results[0].plot(
line_width=3,
font_size=18,
conf=True,
labels=True
)
cv2.imshow("i-TDI Object Detection", annotated_frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()